
SEO using HTML
How to make sure web crawlers index our website the right way?! Learn more now!


I have been working on Front-end development for a while now. It's exciting to build beautiful websites that showcase content that has great business value. The main motive behind building a website/application is to showcase your content online to customers and viewers. You would like to make the content of your website available and accessible on the internet so as to get more business.
One way people look for content they need is by using Search. The results that pop up are the highest ranked and most relevant to the search query. The results we see may differ from one search engine to another. There are many search engines that crawl the web finding new domains and indexing the contents of the web page.
So how do we make sure our webpage is indexed properly and is searchable? The concept which is most important here is Search Engine Optimization (SEO). In this blog post, let us explore ways we can improve SEO by using the right HTML elements.

1. Title
The <title> tag is an HTML element that specifies the title of the webpage. The title tells the search engine and the users about the content of the webpage. The <title> tag must be placed inside the <head> at all times.
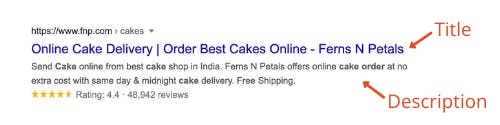
The content of the title appears in the first line when searched on an engine. The title appears in the search page listings, on the title bar of the browser, and also on social media networks. When the link is shared on social media, it appears as a card that has the title shown.
- Keep the title within 50 to 60 characters.
- Use the product/company's name in the title.
- Keep it precise and add in details of discounts/offerings or important services you provide.
- Avoid using all capital letters.
- Put important keywords first which will help in SEO. Make sure to not overuse them in the title.
- Give unique titles for every page on your website.
2. Meta tag
Meta tags are elements that provide information about the HTML page. The data inside meta tags are called metadata and are not visible on the UI of the webpage, but the data can be read by search engines and web crawlers. Search engines use metadata to get more information about the page, for ranking purposes, and also, the data can be displayed in search results.
2.1 Meta description tag
Google displays meta description tags in the search results under the title of the webpage. Hence this has a massive effect on SEO.
<head>
<title>Omeal's Cake Shop - Order online | Designer cakes </title>
<meta name="description" content="Order customer made designer cakes with popular flavours online. Free delivery available in New York City. " />
</head>
Best practices :
- Keep the length within 130-160 characters.
- Add Call to Action words like GET|ORDER|FREE|READ|How To|Easy|Now, etc.
- Include important keywords related to your webpage content. Users usually search keywords hence using keywords will help a great deal.
- Invest time and come up with a unique and best-fitted description as this will be displayed on the search engine.
- Do not stuff the description with a lot of keywords and CTA. Keep it simple and to the point.
2.2 Robots
Robots meta tag is used to give instructions to the web crawlers on how to crawl and index the contents of the webpage. A number of parameters can be assigned to the robots tag based on which the web crawler will know how to index the web page.
<meta name="robots" content="nofollow, noindex" />
Some parameters are :
nofollow: The crawler will not follow any links on the page.follow:The crawler should follow all the links on a page and pass equity to the linked pages.noindex: Tells the search engine not to index the page.index: Tells a search engine to index a page. This is a default meta tag. If no meta tag related to robots is specified, this is used by default.
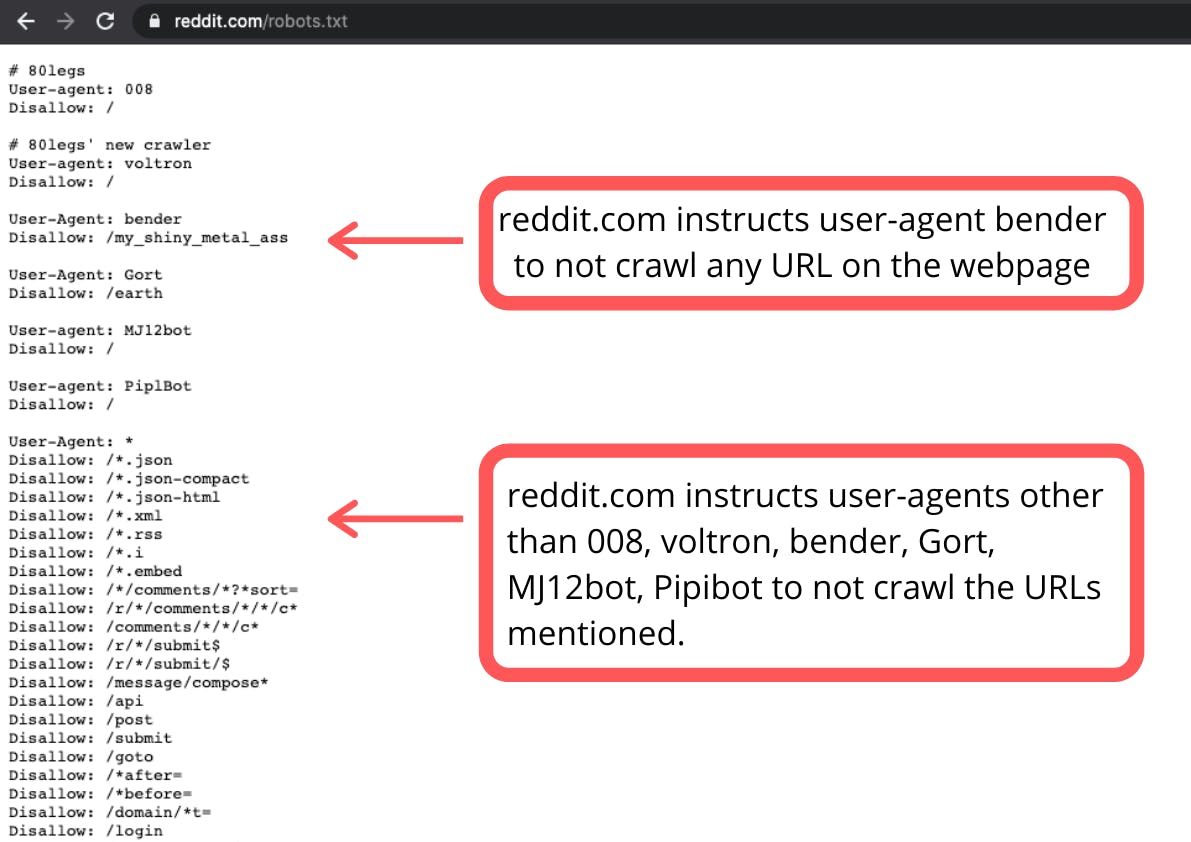
Let's talk about robots.txt file. Search engines follow links to get from one site to another, this is called spidering. When a crawler reaches a webpage, it checks for a robots.txt file. This file contains instructions about how to crawl the website. If the robots.txt file does not contain any directives that disallow a user-agent’s activity, it will proceed to crawl other information on the site.
Best practices:
- Robots.txt file must be placed at the top-level directory. The file must be named 'robots.txt' as it is case-sensitive.
- Every subdomain uses a separate robots.txt file.
- All meta tags (robots or otherwise) are discovered when a URL is crawled. This means that if a robots.txt file disallows the URL from crawling, any meta tag on a page will not be seen and will be ignored.
2.3 Social media tags
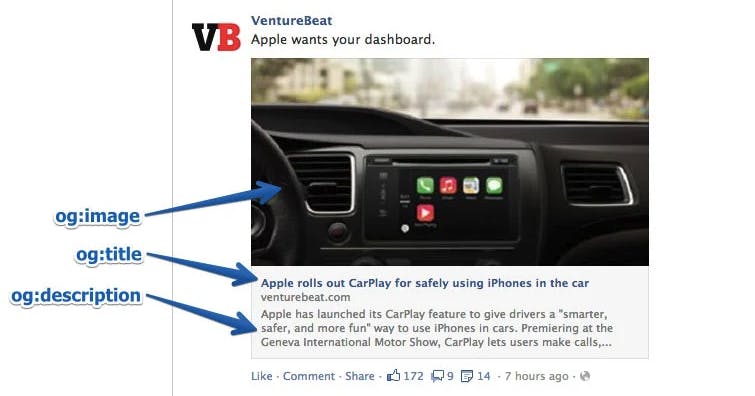
Websites of products and services are shared on social media all the time. Thus social media contributes to search a great deal. People click and view the links they stumble upon on Social media sites. In HTML, Open Graph protocol that is a part of Facebook is used to optimize how websites that are shared on social media platforms are displayed. Here is the official documentation
Open graph tags are placed inside the meta tags. You can specify title, description, URL, image, and others using this tag. Below is an example.
<head>
<meta property="og:title" content="Order the best designer cakes online" />
<meta property="og:description" content="Order customer made designer cakes with popular flavours online. Free delivery available in New York City." />
<meta property="og:url" content:"https://omealcakes.com/order" />
<meta property="og:image" content="https://omealcakes.com/uploads/109091.jpg" />
<meta property="og:type" content="website" />
</head>
<body>
Below is an example from Neil Patel's OG article.
3. Structured data / Schema Markup
Schema Markup is used to describe the content of the webpage to the search engine. Consider an example of 'Orange'. This can mean the color, fruit, and also a company's name. Such content can be misunderstanding sometimes to the search engine. Hence structured data which is written in the format of JSON-LD is used inside the <head> tag under a <script> tag.
Below is an example :
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Product",
"url": "https://omealcakes.com",
"name": "Omeal's Cake shop.",
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+1-XXX-XXX-XXXX",
"contactType": "Customer service"
}
}
</script>
4. Heading Tags
It is easy for search engines to read and index a well-structured webpage. By using heading tags it is easier to tell the search engine the main contents of our webpage. You can match the title of your page with the heading tags as well. Adjust the structure of the webpage elements if needed, but include headings at relevant and at the right places. Do not overuse the heading tags in your content. Be mindful of using keywords for the headings.
<h1> Order cakes online </h1>
5. Alt tags for images
The alt attribute for the image tag is used to give the image context. In case the image itself is not rendered, the alt tag will appear on the webpage and thus the user can understand what the image means. Also, in the case of users who are visually impaired the alt attribute is very useful. Apart from these uses, alt attribute for images also helps in SEO. Web crawlers use the tag to understand image content thus helping in SEO. Also, it is vital if we are looking to rank the Image itself.
<img src="https://omealcakes.com/uploads/109091.jpg" alt="One tier Chocolate Cake"/>
6. Canonical Link
The rel=canonical element, often called the “canonical link,” is an HTML element that helps webmasters prevent duplicate content issues. It is a way of telling search engines that a specific URL represents the master copy of a page.
<link rel="canonical" href="https://omealcakes.com" />
Consider this example :
http://omealcakes.comhttps://omealcakes.comhttp://www.omealcakes.comhttp://omealcakes.com/index.php
All these links look the same to a person but, to a web crawler, all these links are unique. Many search engines crawl thousands of URLs with similar content every day. Due to duplicate content, the search engine can pick an unimportant URL as the main URL. Thus it is important to specify the canonical link in web pages.
Best practices :
- Pick the main URL and include it as the canonical URL for your web pages.
- It is a good idea to put a canonical tag on the homepage of the website.
- Consider two pages with the same content, but one among them is the main page that you need search engines to recognize and showcase on the search page. Keep in mind that canonicalization will prevent the non-canonical sites from ranking, so make sure this use matches your business case.
That's a wrap!!
There might be other factors that prove helpful for SEO in HTML which I might have missed in this article. Do let me know your thoughts in the comments 😊
I had a great time writing it. Well, I hope that the content was helpful. 😇
Reach me out on Twitter.